Principles of Data Structure¶
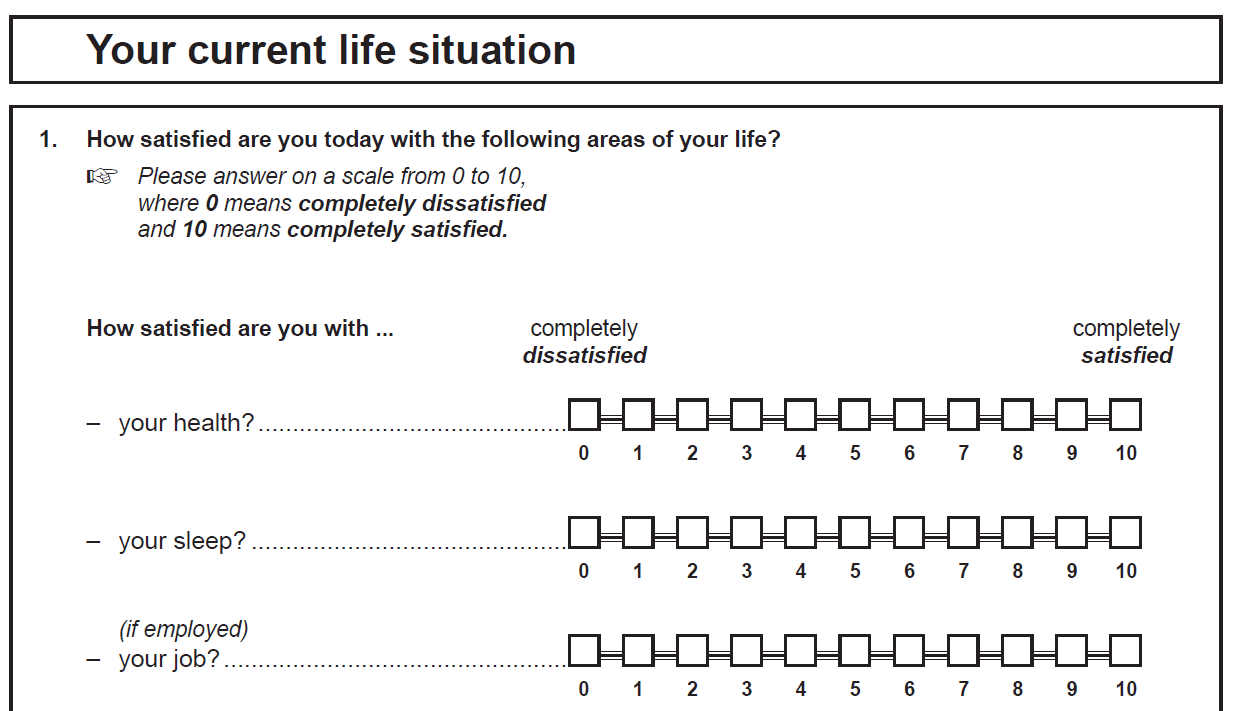
Panel Data Analysis¶
The data structure for panel data consists of three dimensions. At first, the respective examination units (n) and a matrix of dependent and independent variables (y,x) are completely analogous to a cross-sectional design. Another level is the dimension of time (t), whereby a distinction is made between two data formats for panel data structures - “wide” or “long” (with wide format the variable matrix is indexed with the dimension of time and with long format the respective examination units). Regardless of the selected data format, when using panel data with several survey waves, the data matrices are often not completely provided with information due to the panel mortality of individual survey units or because data from new panel members are only collected at a later point in time. In both cases, the term “unbalanced panel data” is used. In contrast, the classical panel data structure, on the other hand, is “balanced”, i.e. as many observations of dependent and independent variables are available for all study units as there are waves of data collection. The data of social science panel data often show a data structure, which is characterized by many investigation units (large n) as well as, in relation to it, few waves and therefore measuring time (small t). When data from a panel study are available, even descriptive forms of data analysis are often of particular interest, since the identification of changes in a variable over time and the corresponding separation of interindividual and intraindividual changes can represent important social facts, particularly in the case of generalizable samples. It is of social scientific interest whether a constant 15 % proportion of people whose income is below the poverty risk level is repeatedly found in the same person over time, or whether there was a even balance of increases and decreases in poverty risks and only half of the population was permanently exposed to the risk. The choice of complex analysis methods for panel data depends first and foremost on the respective measurement level of the dependent and independent variables, but also on whether they are time-constant variables (such as gender or migration background) or time-invariant variables (for an overview see Andreß et al. 2013). The statistical analysis models of panel data range from structural equation models (Finkel 1995), various regression models (Giesselmann/Windzio 2012), event analysis (Blossfeld 2010), sequence data analysis (Brüderl/Scherer 2005), latent growth models (Schiedeck/Wolff 2010) to causal analyses using matching methods (Gangl 2010). A particular advantage of panel data is that the chronological sequence of changes can be modelled and calculated and the problem of unobserved heterogeneity, which is often encountered in the social sciences, can be significantly reduced, at least in comparison with cross-sectional data (Brüderl 2010).
Data Structure of SOEP-Core¶
SOEP-Core contains a multitude of different datasets. To get an overview of the data, a somewhat simplified categorization helps: There are Tracking Data and Survey Data files which describe the development of the sample, such that the user knows which person or household was part of the interviewed sample in any given year. Then there are Original Data files, which contain the data from each year’s questionnaires without any changes except for very basic consistency checks. To help the user with the data, there also are Generated Data. These contain consistently coded variables across all waves with common names, such that the users can easily use this information when combining datasets across waves. The SOEP also provides various data on the respondent’s background, called biographical data. Biography data in general can conceptually be separated into biographical data which are unchanging (such as information on parent’s education, or data from the mother-child questionnaires) and data which may be updated through changes in a respondent’s life (such as new children in the birth biography, or a job change in the job history). Some of the changing data is stored as Spell Data. For each spell there is a definition of the spell type, begin, end point and the censoring status, indicating if a given employment or income spell is censored (left and/or right) or uncensored. One of the biggest assets of the SOEP data is their longitudinal nature, i.e. repeated observations of the same unit (person or household) over time. That`s why we provide longitudinal data sets, such as pl or hl. Finally, there are some files which cannot be easily categorized - some are one-time datasets, some provide information about the interviewers, some about respondents outside of Germany.
There are two datasets which should be the building block of any analysis, as they allow to define longitudinal populations very easily: PPFADL and HPFADL. HPFADL includes all households which have been interviewed successfully at least once. Similarly, PPFADL contains all persons who have ever lived in a household that has participated in the SOEP, i.e. that has been captured in HPFADL, including non-respondents and children. Both data files contain one record per household or person, respectively, with wave-specific variables for each year’s survey status. In addition to some time-invariant information (like gender, year of birth, migrant status), these files contain all necessary identifiers to combine other files with PPFADL and HPFADL.
Although they provide essential information, PPFADL and HPFADL alone are of little use for actual analyses. The most often used sources for additional information in SOEP-Core are the cross-sectional data files provided in each survey year (or “wave”) or the data sets in the long-format.
Cross-sectional data files (CS)¶
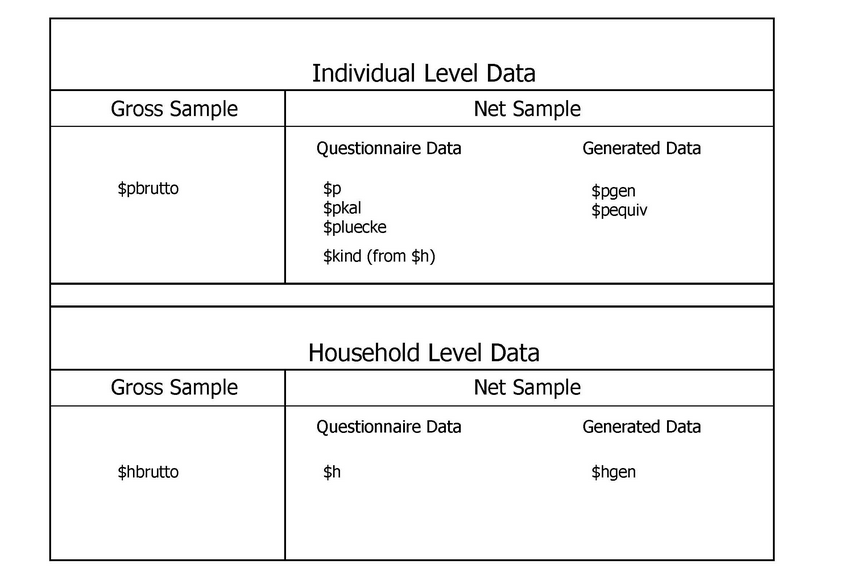
Each wave is identified by letters of the alphabet: the first wave in 1984 is wave “A”, 1985 is wave “B”, and so on. To simplify the notation, the “$” sign is used, when all waves of one group of datasets are referred to. For example, $H refers to all household level datasets AH to now. For each year of SOEP data there are single data files for households (e.g. $H) as well as for individual respondents (e.g. $P) and children (e.g. $KIND) based on interview information. These observations make up the “net” population, with each of these files containing as many records as interviews could be conducted. Additional data files with a limited number of variables based on the “address log” constitute the “gross” number of households and persons, i.e. all households and their members which were eligible for an interview in any given year.
Data structure
Cross sectional data is a type of data, which observes many subjects at the same point of time. Each person is assigned a row in the data set and is only included once in such a data set. By merging cross-sectional SOEP data across waves (e.g. „bfp“ and „bgp“), you receive a dataset in wide-format.
Data Structure in wide-format (wide)¶
The SOEP data is offered in different data structures. In wide format, a respondent’s repeated responses are displayed in a single row and each response in a separate column. Each column represents a variable. We provide 4 datasets in wide-format: ppfad, phrf, hpfad, hhrf
| row | ID | syear | sex | income |
|---|---|---|---|---|
| 1 | 1 | 2016 | m | 1500 |
| 2 | 2 | 2016 | m | 1000 |
| 3 | 6 | 2016 | f | 2000 |
| 4 | 8 | 2016 | m | 5500 |
Data Structure in long Format (long)¶
The long format is a compressed and user-friendly data set structure for longitudinal section analysis. Here, each person has one line per survey year. This means that you do not have several data sets for the different waves, but a data set in which all survey waves are represented. A person can occur more than once in such a data set. In long format, one line describes a person-year combination.
| Row | ID | syear | sex | income |
|---|---|---|---|---|
| 1 | 1 | 2010 | f | 1500 |
| 2 | 1 | 2011 | f | 1500 |
| 3 | 1 | 2012 | f | 2000 |
| 4 | 2 | 1999 | m | 5500 |
| 5 | 2 | 2000 | m | 5500 |
Data Structure in spell format (spell)¶
In the strict sense of the word, spell data are about time periods with a defined start and end. When handling spell data it is necessary to take potential censoring into account. Censoring denotes that the beginning (left censored) or ending (right censored) of a spell is imprecise because of missing information or the beginning or ending of a spell is outside of the period of observation. It is quite conceivable that a person has only one spell over a given period, such as a male who is full-time employed. For a ten year period, there may be just the one spell “full-time employed”. In panel data, the same person would have 10 observations, one per year. A person may have many spells over a time period, and even have overlapping spells, like working part-time and receiving a disability pension. Spell data is useful for looking at stays in a certain state, and transitions in and out of that state.
| Row | ID | spellnr | spelltype | begin | end | censored |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | Retired | 1983 | 2007 | left and right censored |
| 2 | 1 | 2 | Housewife/husband | 1983 | 1984 | left censored |
| 3 | 1 | 3 | Housewife/husband | 1994 | 1994 | uncensored |
| 4 | 1 | 4 | Housewife/husband | 1998 | 1998 | uncensored |
| 5 | 2 | 1 | Full-Time Employment | 1984 | 1984 | left censored |
| 6 | 2 | 2 | Full-Time Employment | 1985 | 1985 | uncensored |
Here are some recommended literature suggestions:
Working with spell data:
Working with spell data (pdf):
Working with spell data (do-files):
How to generate spell data from data in wide format: Based on the Migration Biographies of the IAB-SOEP Migration Sample:
Data Sets SOEP-Core¶
In the SOEP, each survey year is allocated to a data wave, which is abbreviated with the letters of the alphabet. The current data wave can contain several versions, which are displayed in SOEP with a “v” for version and the respective version number. The version number represents the survey years since the beginning of the survey. The SOEP has recently published the 34th version since the survey began in 1984. Within a data wave, updates may occur over time, such as v34.1. If updates have been carried out, users are informed about them via various information channels and asked to order the data again. After ordering the data, the data will be sent to you as a zip-file.

Within this zip file you will find various data sets and a “RAW” subdirectory.
The data sets above the “RAW” subdirectory are highly compressed and an easy to analyze version of the SOEP data.

The data in SOEP-Core are no longer only provided as wave-specific individual files but rather pooled across all available years (in “long” format). In some cases, variables are harmonized to ensure that they are defined consistently over time. For example, the income information provided up to 2001 is given in euros, and categories are modified over time when versions of the questionnaire have been changed. The longitudinal nature is one of the biggest assets of the SOEP. That`s why we provide longitudinal data sets, such as pl or hl. The advantage of such a data set is that longitudinal analyses can be carried out without great effort.
If you need more information about the long data structure visit the chapter Data Structure in long Format (long).
In the “RAW” directory you will find all wave-specific data sets that were used to generate the long data sets on the previously presented level.

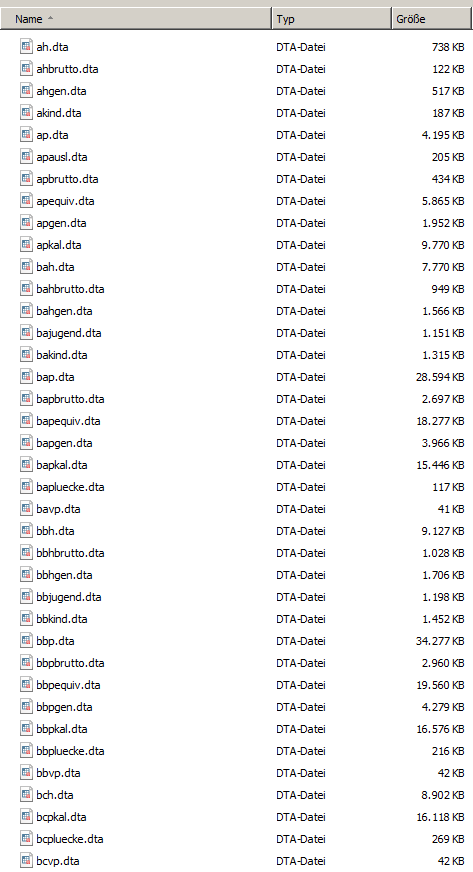
Within this “RAW” directory, the data sets are stored on a wave-specific basis and are the generation basis for the majority of the long data sets described above. In addition to these wave-specific data sets, the “RAW” directory also contains additional data sets in cross-sectional format that have not yet been distributed in long format ($school, $school2, ev, exit, $pkalost and pbr_hhchch).
To understand the data set and variable names, visit the Labeling SOEP-Core chapter.
Overview Data Sets¶
Your data distribution file contains five different types of data sets:
| Tracking Data | Original Data | Survey Data | Generated Data | Spell Data |
|---|---|---|---|---|
| hpfad | abroad | csamp | bioage17 | artkalen |
| hpfadl | biol | design | bioagel | biocouplm |
| $hbrutto | ev | exit | biobirth | biocouply |
| hbrutto | $h | hhrf | bioedu | biomarsm |
| $pbrutto | hl | pbr_hhch | bioimmig | biomarsy |
| pbrutto | $host | phrf | biojob | einkalen |
| pbr_exit | $jugend | bioparen | lifespell | |
| ppfad | jugendl | bioresid | migspell | |
| ppfadl | lueckel | biosib | pbiospe | |
| $p | biosoc | refugspell | ||
| pl | biotwin | sozkalen | ||
| $pausl | camces | |||
| $pluecke | cogdj | |||
| $post | cognit | |||
| $school | gripstr | |||
| $school2 | hconsum | |||
| $vp | health | |||
| vpl | $hgen | |||
| hgen | ||||
| hwealth | ||||
| interviewer | ||||
| kidl | ||||
| $kind | ||||
| mihinc | ||||
| $pequiv | ||||
| pequiv | ||||
| pflege | ||||
| $pgen | ||||
| pgen | ||||
| $pkal | ||||
| pkal | ||||
| $pkalost | ||||
| pwealth | ||||
| timepref | ||||
| trust |
Tracking Data¶
Tracking data are the basis for linking your research-relevant variables. In addition to various demographic information, tracking data also provide information on how the interview is conducted. These data sets should be understood by you as initial data. You can use the tracking data to merge your research-relevant variables via the person and household numbers.
| Dataset | Label | Format | Identifier (ID) | Special Identifier |
|---|---|---|---|---|
| hpfad | Household Tracking File | wide | hhnrakt, $hhnr | |
| hpfadl | Household Tracking File | long | hid, syear, cid | |
| $hbrutto | Gross Household Data | wide | hhnrakt, hhnr | intid1, intid |
| hbrutto | Gross Household Data | long | hid, syear, cid | intid1, intid |
| pbr_exit | Cumulated Exit | long | pid, hid, syear, cid | hhnrold |
| $pbrutto | Gross Individual Data | wide | persnr, hhnrakt, hhnr | $hhnrold |
| pbrutto | Gross Individual Data | long | pid, hid, syear, cid | intid, hhnrold |
| ppfad | Individual Tracking File | wide | persnr, hhnr, $hhnr, | |
| ppfadl | Individual Tracking File | long | pid, hid, syear, cid | parid |
hpfad „Household Tracking File" (wide) : For all years since 1984, the HPFAD data set contains information on all households that have ever participated in the SOEP survey at any point in time. HPFAD is important for the delimitation of the examination unit (household), especially for longitudinal analyses. HPFAD is particularly suitable for household analyses and can be used for preselection of specific households.
hpfadl „Household Tracking File“ (long): HPFADL consists of all waves of the data sets hpfad „Household Tracking File" (wide) and hhrf „Weighting and staying probabilities“ (wide) of SOEP-Core.
$hbrutto „Gross Household Data“ (CS) $HBRUTTO covers all households, who were successfully interviewed for the first time in wave $ or were contacted for the purpose of being interviewed again in wave $. The data sets provide gross cross-sectional information on all SOEP households’ interviews as well as their positions in the panel frame work.
hbrutto „Gross Household Data“ (long): HBRUTTO consists of all waves of the data sets $hbrutto „Gross Household Data“ (CS) of SOEP-Core.
pbr_exit„Cumulated Exit“ (long): :
$pbrutto „Gross Individual Data“ (CS) : $PBRUTTO covers all respondents, who were successfully interviewed for the first time in wave $ or were contacted for the purpose of being interviewed again in wave $. The data set provides gross cross-sectional information on all SOEP respondents’ interviews as well as their positions in the panel frame work.
pbrutto „Gross Individual Data“ (long): PBRUTTO consists of all waves of the data sets $pbrutto „Gross Individual Data“ (CS) of SOEP-Core.
ppfad „Individual Tracking File“ (wide) : For all years since 1984, the PPFAD data set contains information on all persons who have ever lived in a SOEP household at a survey time (i.e. all respondents, but also children under 17 years of age and persons who have never given an interview). PPFAD is important for the delimitation of the examination units (persons), especially for longitudinal analyses.
ppfadl „Individual Tracking File“ (long): PPFADL consists of all waves of the data sets ppfad „Individual Tracking File“ (wide) and phrf „Weighting and staying probabilities“ (wide) of SOEP-Core. It contains one record for each individual and year a person has been a member of a respondent household. It is keyed on PID, the Cross-Wave Person Identifier, and SYEAR, the survey year identifier. It contains the Household ID, and never changing individual characteristics, individual weights, as well as the response status, for that individual at each wave.
Original Data¶
These data sets contain the direct information of the respondents. The contents of these variables are 1:1 the contents of the survey instruments. By searching in the questionnaires you can determine the exact wording of the question or also possible filter guidance.
| Dataset | Label | Format | Identifier (ID) | Special Identifier |
|---|---|---|---|---|
| abroad | Questionnaire for people moved abroad | long | persnr, hhnrakt, syear, hhnr | |
| biol | Biographical Data | long | pid, hid, syear, cid | intid |
| ev | First wealth module | wide | persnr, hhnrakt, hhnr | |
| $h | Household questionnaire | wide | hhnrakt, syear, hhnr | intid |
| hl | Household questionnaire | long | hid, syear, cid | intid |
| $h_refugees | Household questionnaire Refugee Sample | wide | hhnrakt, syear, hhnr | intid |
| ghost | East specific questions from the Household questionnaire | wide | hhnrakt, hhnr | intid |
| $jugend | Youth questionnaire for first time respondents at age 17 | wide | persnr, hhnrakt, syear, hhnr | intid |
| jugendl | Youth questionnaire for first time respondents at age 18 | long | pid, hid, syear, cid | intid |
| $p | Personal questionnaire | wide | persnr, hhnrakt, syear, hhnr | intid |
| pl | Personal questionnaire | long | pid, hid, syear, cid | intid |
| $p_mig | IAB-SOEP Migration Sample: Original Individual questionnaire | wide | pid, hid, syear, cid | intid |
| $p_refugees | Personal questionnaire Refugee Sample, incl. Biography | wide | persnr, hhnrakt, syear, hhnr | intid |
| $pausl | Migrant specific questions in the Personal Questionnaire | wide | persnr, hhnrakt, hhnr | |
| $pluecke | Follow-Up Questioning | wide | persnr, hhnrakt, hhnr | intid |
| $school | Questionnaire: Early Youth, 12-13 years old | wide | persnr, hhnrakt, syear, hhnr | intid |
| $school2 | Questionnaire: Early Youth, 14-15 years old | wide | persnr, hhnrakt, syear, hhnr | intid |
| $vp | Questionnaire: the deceased person | wide | persnr, hhnrakt, syear, hhnr | vpersnr, intid |
abroad „Questionnaire for people moved abroad“ (CS): With the pilot study ”Life outside Germany” in 2008, the longitudinal German Socio-Economic Panel Study (SOEP) ventured into completely uncharted methodological territory by attempting to locate the addresses of former participants in the German household panel study SOEP who have since immigrated abroad, and to survey these individuals with the help of a specially developed written questionnaire on the reasons for their international move. The project was discontinued due to insufficient case numbers in 2014.
biol "Biographical Data" (long): BIOL contains cumulated individual-level data from the biographical questionnaire.
ev „First wealth module“ (long):
$h „Household questionnaire“ (CS): The $H-files contain all questions of the household questionnaire.
hl „Household questionnaire“ (long): HL contains all waves of the data sets $h „Household questionnaire“ (CS): from SOEP-Core.
h_refugees „Household questionnaire Refugee Sample“ (CS): The $H-files contain all questions of the household refugees questionnaire.
only 1990
ghost „East specific questions from the Household questionnaire“ (CS): The $host file contains east specific questions from the household questionnaire. For the year 1990 the data provides information about east specific topics about the German reunification i.e. presents from the BRD.
$jugend „Youth questionnaire for first time respondents at age 17“ (CS) : Since 2000 (wave Q), first-time respondents between the ages of 16 and 17 have received a separate biographical questionnaire with additional age-group-specific questions, for instance, about their relationship to their parents or about what they do in their free time. Up to now, only some of the data collected from this survey have been processed and provided to users in dataset BIOAGE17. The complete data will be provided in individual $JUGEND datasets.
jugendl „Youth questionnaire for first time respondents at age 17“ (long): JUGENDL contains the waves q (2000) up to the current wave of $jugend „Youth questionnaire for first time respondents at age 17“ (CS) of SOEP-Core.
$p „Individual questionnaire“ (CS): The $P-files contain all variables of the individual questionnaire for the wave $. In addition, the individual-specific data of the samples IAB-SOEP Migration and IAB-BAMF-SOEP Refugee Survey are integrated in the original $P data set.
pl „Individual questionnaire“ (long): The PL data set contains all waves of the $p „Individual questionnaire“ (CS): data sets of SOEP-Core. In addition, the PL file contains all variables of all waves of the data sets $post „East specific questions from the Individual questionnaire“ (CS) and $pausl „Migrant specific questions in the Individual Questionnaire“ (CS) .
2013-2016
$p_mig „IAB-SOEP Migration Sample: Original Individual questionnaire“ (CS): The original data from the Sample M specific survey instrument can be found in the dataset $P_MIG, combining the individual and the biographical questionnaire. Since the current version “v34”, the data set is not part of the SOEP-Core distribution file anymore and has to be ordered separately. The variables are included in original or generated datasets. Variables equivalent to variables in the individual questionnaire of other samples are included in the dataset $P, Variables equivalent to variables in the biography questionnaire of other samples are included in the respective biography dataset (e.g. BIOMARSM), the comprehensively surveyed migration biography can be found in the new dataset MIGSPELL.
only 2016
$p_refugees „IAB--BAMF-SOEP Survey of Refugees in Germany: Original Individual questionnaire“ (CS): The original data from the survey instruments used in Samples M3 and M4 can be found in original format in the dataset $P_REFUGEES, where the individual and the biographical questionnaires are combined. Since the current version “v34”, the data set is not part of the SOEP-Core distribution file anymore and has to be ordered separately. The variables are integrated in original or generated datasets. Variables equivalent to those in the individual questionnaire of other samples are included in the dataset $P. Also included in $P are all variables which will be asked more than once, but specific to the refugee questionnaire, Variables equivalent to those in the biographical questionnaires in other samples are included in the respective biographical datasets (e.g., BIOMARSM), the comprehensively surveyed migration biography can be found in the new dataset REFUGSPELL.
1984-1995
$pausl „Migrant specific questions in the Individual Questionnaire“ (CS) :
$pluecke „Follow-Up Questioning“ (CS): Temporary drop-outs (“gaps”) can cause problems for longitudinal analyses. This is especially true for the employment and income data stored. That is why the SOEP tries to fill in at least some of the central missing information. $PLUECKE is a small questionnaire covering information on the year previous to which the drop-out occurred. This covers questions on job-related changes, calendar of occupation, income, education and qualification.
$post „East specific questions from the Individual questionnaire“ (CS) : The $post files contain east specific questions from the individual questionnaire. For the years 1990 and 1991 the data provides information about east specific topics.
$school „Questionnaire: Early Youth, 12-13 years old“ (CS): Since 2014 the $SCHOOL-files contain all variables of the „Pre-teen (Schülerinnen und Schüler)“ questionnaire. Therefore the data sets provide variables about school, home, leisure time, health, self-perception and relationships with friends, siblings and parents.
$school2 „Questionnaire: Early Youth, 14-15 years old“ (CS): Since 2016 the $SCHOOL2-files contain all variables of the „Early Youth (Frühe Jugend)“ questionnaire. Therefore the data sets provide variables about self-perception, independence, school, leisure time or relationships with friends, siblings and parents.
$vp „Questionnaire: the deceased person“ (CS): The $VP-files contain information about respondents who lost a person in the previous year. It provides information about the deceased person and the respondent who reported the case of death.
Survey Data¶
These data sets contain surveymethodical information for SOEP core. The various data sets provide detailed exit information from respondents or household weighting factors that you need for representative analyses.
| Dataset | Label | Format | Identifier (ID) | Special Identifier |
|---|---|---|---|---|
| csamp | Sample Definition | long | cid | |
| design | Survey Design | wide | hhnr | intid |
| exit | Cumulative drop-outs | wide | persnr, hhnr, syear | |
| hhrf | Weighting and staying probabilities | wide | hhnrakt, hhnr | |
| pbr_hhch | PBR_HHCH | wide | persnr, hhnrakt, syear, hhnr | pnralt, pnrneu, hhnrold |
| phrf | Weighting and staying probabilities | wide | persnr, hhnr |
csamp „Sample Definition“ (long):
design „Survey design“ (CS) : The dataset DESIGN provides information on the stratified sampling of the SOEP in form of two variables. The variable STRAT identifies each of the discrete sampling groups described above. Altogether, the SOEP consists of 40 strata: one stratum in sample A, twenty-seven in sample B, one in sample C, three in sample D, one in sample E, two in sample F, four in sample G, and one in sample H. Unique inclusion probabilities pertain to each of these strata. The variable DESIGN contains the inverse of this probability, i.e., the design weight.
exit „Cumulative drop-outs“ (CS):
hhrf „Weighting and staying probabilities“ (wide) : In the SOEP database, different weighting variables for cross-sectional as well as for different kinds of longitudinal weighting are set aside for each household in the HHRF-file.
phrf „Weighting and staying probabilities“ (wide) : In the SOEP database, different weighting variables for cross-sectional as well as for different kinds of longitudinal weighting are set aside for each person in the PHRF-file.
Generated Data¶
The SOEP team has prepared these data sets for you in a special way. The data sets are prepared in a research-friendly manner and are subjected to additional plausibility checks and quality controls. They usually consist of several variables, of different survey instruments and are described by the documentation provided. Therefore, these data sets cannot be assigned 1:1 to a survey instrument.
| Dataset | Label | Format | Identifier (ID) | Special Identifier |
|---|---|---|---|---|
| bioage17 | Generated biographical youth information | wide | persnr, hhnrakt, syear, hhnr | bymnr, byvnr, intid |
| bioagel | Generated biographical information | long | persnr, hhnrakt, syear, hhnr | persnre |
| biobirth | Generated biographical information | wide | persnr, hhnr | kidpnr01-kidpnr15 |
| bioedu | Generated biographical information | wide | persnr, hhnr | |
| bioimmig | Generated biographical information | long | persnr, hhnrakt, syear, hhnr | |
| biojob | Generated biographical information | wide | persnr, hhnr | |
| bioresid | Generated biographical information | wide | persnr, hhnrakt, syear, hhnr | intid |
| biosib | Generated biographical information | wide | persnr, hhnr | sibpnr1-sibpnr11 |
| biosoc | Generated biographical information | wide | persnr, hhnrakt, syear, hhnr | intid |
| biotwin | Generated biographical information | wide | persnr, hhnr | pnrtwin, pnrtrip, pnrquad |
| camces | Highest Educational Qualification, Migrants Sample M1 and M2 | wide | persnr, hhnrakt, syear, hhnr | |
| cogdj | Data on cognitive tests (Youth) | wide | persnr, syear, hhnr | |
| cognit | Data on cognitive potential | wide | persnr, syear, hhnr | intid |
| gripstr | Measures grip strength | wide | persnr, syear, hhnr | intid |
| hconsum | Hosehold Consume Module | wide | hhnrakt, syear, hhnr | |
| health | Data on health indicators | wide | persnr, syear, hhnr | |
| $hgen | Generated Household Data | wide | hhnrakt, hhnr | |
| hgen | Generated Household Data | long | hid syear cid | |
| hwealth | Wealth Module | long | hhnrakt, syear, hhnr | |
| interviewer | Data on the SOEP Interviewer | long | hhnr, syear | intid |
| kidlong | Data on children | long | persnr, hhnrakt, syear, hhnr | |
| $kind | Data on children (from HH-Questionnaire) | wide | persnr, hhnrakt, hhnr | |
| mihinc | Multiple imputed data on monthly household income | long | hhnrakt, syear, hhnr | |
| $pequiv | Cross-national Equivalent File | wide | persnr, hhnrakt, syear, hhnr | |
| pflege | Persons needing care within the household | long | persnr, syear, hhnr | |
| $pgen | Generated Individual Data | wide | persnr, hhnrakt, hhnr | |
| pgen | Generated Individual Data | long | pid, hid, syear, cid | |
| $pkal | Individual Calendar | wide | persnr, hhnrakt, hhnr | |
| pkal | Individual Calendar | long | pid, hid, syear, cid | |
| $pkalost | Individual Calender | wide | persnr, hhnrakt, hhnr | |
| pwealth | Wealth Module | long | persnr, hhnrakt, syear | |
| timepref | Experiment on time preferences | wide | persnr, hhnrakt, syear, hhnr | |
| trust | Experiment on trust | long | persnr, hhnrakt, syear, hhnr |
bioage17 „Generated biographical information“ (CS): The design of the dataset BIOAGE17 is patterned after the 2001 Youth Questionnaire, which is the standard version for subsequent years. A special group of first time respondents are young persons living in a panel household, who reach the surveying age of 17 years. From this specific group of panel entrants, we are able to obtain some more detailed information on youth and socialisation than from other new sample members.
bioagel „Generated biographical information“ (long): The BIOAGEL data files are generated using information collected in the “Mother & Child” and “Parent” questionnaires. BIOAGEL is now provided in one dataset.
biobirth „Generated biographical information“ (CS): The file BIOBIRTH provides information on fertility histories of adult respondents in the SOEP. Until 2014 (version 30, wave BD) the data was stored in two separate files: BIOBIRTH containing female fertility histories, and BIOBRTHM providing male fertility histories. Fertility histories in BIOBIRTH provide information on every woman (as well as every man with a panel entry since 2001) who has ever provided at least one successful SOEP interview.
bioedu „Generated biographical information“ (CS): The Socio-Economic Panel Study (SOEP) contains a broad range of variables which cover early child education and care, educational participation, educational degrees and other related topics. It is the aim of the BIOEDU dataset to provide ready-made variables on educational transitions and related topics in order to support analyses in a longitudinal perspective.
bioimmig „Generated biographical information“ (long): The variables contained in BIOIMMIG deal with questions related to foreigners in (and migrants to) Germany. Specifically, questions concerning desire to return to the home country, the presence of relatives in the home country, reasons for coming to Germany, and conditions upon initial arrival in Germany.
biojob „Generated biographical information“ (CS): The purpose of BIOJOB is to provide a file, that offers the user convenient access to biographical information on past job activities. BIOJOB consists of generated variables as well as plain questionnaire information. Up to now all but two variables of BIOJOB are time-invariant. Information on occupational changes and on the age at the most recent change of occupation refer to the date of the respondent’s biography interview.
bioresid „Generated biographical information“ (CS): In 1994 questions with a focus on occupancy were introduced to the Biographical Questionnaire asking for the duration of residence in the current dwelling and any second residence. The information surveyed in the Biographical Questionnaire is stored in the file BIORESID.
biosib „Generated biographical information“ (CS): BIOSIB provides information on siblings living within the SOEP households. The data set contains the person numbers of all siblings in an observed family. It includes information on their sex, their year of birth, the number of siblings, the individual’s position within the birth order, and on the relationship between the observed siblings.
biosoc „Generated biographical information“ (CS): BIOSOC contains retrospective data on youth and socialization. Respondents of all ages describe aspects of their life at the age of 15, including their relationship with parents, grades in school, the federal state where they last attained educational qualifications, detailed information on vocational qualifications, as well as intentions to complete further education or vocational training. Questions concerning military and alternative services are also included in this data set.
biotwin „Generated biographical information“ (CS): The file BIOTWIN contains all twins that were ever identified within the SOEP. To be classified as a twin, a person is required to have exactly the same age as his or her sibling (year & month of birth), have a relationship to the head of the household that indicates that he or her and a second persons are siblings, and have the same mother (as far as a pointer to the mother is available). Furthermore, it is not only twins that are recorded in the BIOTWIN data set, but also triplets or quadruple siblings.
camces „Highest Educational Qualification, Migrants Sample M1 and M2“ (CS): The CAMCES-File provides information about Computer-Assisted Measurement and Coding of Educational Qualifications in Surveys.
cogdj „Data on cognitive tests (Youth)“ (CS): In SOEP 2006, a separate questionnaire with cognitive tests for adolescents was used for the first time: “Lust auf DJ”. In this case, “DJ” stands for “Thinking Sports and Youth (Denksport und Jugend)”, but was also specifically selected to arouse the more common association of “Disc Jockey”. For all interviewees aged 16 - 17 years, the questionnaire “Lust auf DJ” was used and created.
cognit „Data on cognitive potential“ (long): In the 2006 survey year, for the first time, short cognitive tests were carried out with a subsample of the SOEP. The goal was to employ a robust set of instruments that could be administered easily by trained interviewers within just a few minutes. Im COGNIT06 werden den Nutzern die aggregierten Summen-Scores (jeweils Gesamtwerte für drei Zeitpakete, sog. „parcels“ von 30, 60 und 90 Sekunden) zur Verfügung gestellt.
gripstr „Measures grip strength (left and right hand)“ (long): The data on grip strength from the survey year 2012 is now included in the GRIPSTR dataset.
hconsum „HH consume module“ (CS)“: We were faced with three methodological challenges in generating the final consumption data. Firstly, due to the design of the consumption module, inconsistent answers arose between the monthly and annual amounts spent for consumption. Secondly, we encountered the well-known phenomenon of missing data, here in particular item nonresponse. And thirdly, consumption data are usually blurred by heaping. For researchers who do not want their consumption variables to include changes from all steps of data preparation, the new data set “HCONSUM” contains not only the prepared consumption variables but also flag variables providing researchers the opportunity to select individual solutions.
health „Data on health indicators“ (long): Starting in 2002 the SOEP health module in the individual questionnaire has been revised and put into a two year replication period. In the HEALTH-File users find i.e. the generated variables on height and weight with imputation flags and a user-friendly longitudinal checked generated variable of the Body Mass Index (BMI).
$hgen „Generated Household Data“ (CS) : In order to minimize computing efforts for the user, the SOEP provides yearly status variables on household level. The $HGEN data provides a set of time-consistent variables generated from the SOEP household questionnaire. It only includes households who participated in the respective year.
hgen „Generated Household Data“ (long): HGEN contains all waves of the $hgen „Generated Household Data“ (CS) data sets of SOEP-Core.
hwealth „Wealth module“ (long): The generated SOEP wealth data is stored in two separate data files called PWEALTH for information at the individual level and HWEALTH for correspondingly aggregated data at the household level. HWEALTH contains all information on the household level; it is purely the result of aggregating the person-level information in PWEALTH. However for all persons with valid household level information that did refuse to respond to the Individual questionnaire (partial unit non-response) imputations have been carried out and the results are included in HWEALTH.
interviewer „Data on the SOEP Interviewer“ (long): The SOEP does not only aim at collecting high-quality data on the living conditions and well-being of households, but –as a by-product of internal quality assurance processes– it lends itself increasingly as a empirical source for survey research. The purpose of the INTERVIEWER file is to provide user convenient access to all available, longitudinal information on the SOEP interviewers.
kidlong „Data on children“ (long) : The variables stored in the KIDLONG file are based on the information annually collected and stored in the wave-specific $KIND files. The relevant information is not provided by children themselves but by answers to the questions in the household questionnaire given by the respondent within the household (mostly the head of the household). This data is reaggregated at the person level and stored as child-specific entries in the file $kind „Data on children (from HH-Questionnaire)“ (CS): .
$kind „Data on children (from HH-Questionnaire)“ (CS): The variables from the annual $kind files are not based on answers provided by the children themselves, but by answers provided by the head of household. This data is re-aggregated on the person level and saved as child-specific entries in the file $kind. The annual $kind datasets also contain additional information on institutional care and school attendance for children and young people.
mihinc „Multiple imputed data on monthly household income (long)“: The dataset MIHINC contains the complete imputation results and is separately available. To be compatible with methods for analysing multiply imputed data, MIHINC is constructed in the so called stacked or MIM Dataset Format. It contains the following variables: HHNRAKT, SVYYEAR, MJ, MI, IHINC and IMPFLAG. Since 1995 for every survey household in all survey years there are ten imputed values for the current household income.
$pequiv „Cross-national Equivalent File“ (CS) : The $PEQUV-File is based on the Cross-National Equivalent File (CNEF) with extended income information for the SOEP. This file comprises not only the aggregated income figures provided in the CNEF but also further single income components.
pequiv „Cross-national Equivalent File“ (long) PEQUIV contains all waves of the $pequiv „Cross-national Equivalent File“ (CS) data sets of SOEP-Core.
pflege „Persons needing care within the household“ (long): Since wave B (1985) the SOEP household questionnaire includes questions on household members in need of care. In order to support analyses on an individual level, this information has been restructured and stored in the cumulative file PFLEGE.
$pgen „Generated Individual Data“ (CS): The $PGEN-files contain user friendly data on the individual level which are consolidated from different sources. The plausibility is in many respects longitudinally validated, therefore the data here are in most situations superior compared to the data in $P. The file contains one row for each person (persnr is unique) with a completed individual or youth questionnaire.
pgen „Generated Individual Data“ (long): PGEN contains all waves of the $pgen „Generated Individual Data“ (CS): data sets of SOEP-Core.
$pkal „Individual Calendar“ (CS) : The $pkal datasets contain calender variables from the Individual questionnaire. The dataset includes the activity status on a monthly basis as well as the income status of a person.
pkal „Individual Calendar“ (long) PKAL contains all waves of the $pkal „Individual Calendar“ (CS) data sets of SOEP-Core.
1990-1991
$pkalost „Individual Calendar“ (CS):
pwealth „Wealth module“ (long): In the year 2002, the individual questionnaire included for the first time a special module focusing on wealth. This section included questions on seven different wealth components: Owner-occupied property (including debt), other property (including debt), financial assets, private pensions (including life insurance and building savings contracts), business assets, tangible assets and consumer credit. The generated SOEP wealth data is stored in two separate data files called PWEALTH for information at the individual level and HWEALTH for correspondingly aggregated data at the household level. Wealth-related variable names in the file PWEALTH consist of six digits. The first digit tells the user which wealth component is referred to, and the second to sixth digits provide more detailed information about possible filter information, the personal share, the gross amount, and the amount of any outstanding debt. In principle a digit is coded “1” if a given variable does indeed contain this specific piece of information and “0” otherwise. The wealth information in the SOEP questionnaire is surveyed at the individual level and thus also imputed or edited at the individual level (although checked against household information for consistency).
timepref „Experiment on time preferences“ (CS): Following on the behavioral experiment on trust and trustworthiness carried out in the 2003, 2004, and 2005 SOEP surveys, the experiment “time preferences” was run in 2006. In this experiment on economic behavior, respondents were asked to decide how they would want to receive €200 in prize money: if they would want to receive it immediately by check, or if they would want to wait and receive a larger amount later—that is, with interest.
trust „Experiment on trust“ (long): Data set of the economic behavior experiment on trust and trustworthiness from the survey years 2003, 2004 & 2005, which serves to measure trust, based on an investment game. This is a one-off game for two actors who relate to each other anonymously. The first player receives a credit of ten points and can overwrite any number of points of the second player. Each overwritten point is doubled. The second player also receives a credit of ten points. After receiving the (doubled) points from the first player, it decides how much of its own credit it will transfer to the first player (zero to ten points). As with the first transfer, your points at the recipient are doubled. After the decision of the second player, the game ends and the other players are paid their income (one point corresponds to one euro, the sum is sent out as a cheque a few days later). The TRUST data set thus contains the information from all three waves in which the behavioral experiment was conducted.
Spell Data¶
General information about spell data in the SOEP can be found in the chapter Data Structure in spell format (spell)
| Dataset | Label | Format | spellnr | Special Identifier |
|---|---|---|---|---|
| artkalen | Spell data from the activity calendar | wide | persnr, hhnr | |
| biocouplm | Generated biographical information | long | persnr, hhnr | coupid |
| biocouply | Generated biographical information | long | persnr, hhnr | |
| biomarsm | Generated biographical information | long | persnr, hhnr | |
| biomarsy | Generated biographical information | long | persnr, hhnr | |
| einkalen | [deprecated] Spell data on income | long | persnr, hhnr | |
| lifespell | Spell Information on the Pre- and Post-Survey History of SOEP-Respondents | long | persnr, hhnr | |
| migspell | Migration history | long | persnr, hhnr | |
| pbiospe | Generated biographical information | long | persnr, hhnr | |
| refugspell | Migration history | long | persnr, hhnr | |
| sozkalen | [deprecated] Spell data on social benefits | long | hhnrakt, hhnr |
artkalen „Spell data from the activity calendar“ (long) : The ARTKALEN contains spells (monthly) for events starting in January 1983. This is in contrast to PBIOSPE, where spells were in yearly durations, and events previous to 1983 were included. The information on activity status are collected on a monthly basis in the yearly Individual questionnaire and stored in the file ARTKALEN.
biocouplm „Generated biographical information“ (long): With the BIOCOUPLM the SOEP provides consistent and continuous partnership histories for nearly all adult respondents. BIOCOUPLM is build on the prospective information at the time of each interview. The relationsship histories are collected on a monthly basis from all adult SOEP-participants since their entry into the SOEP.
biocouply „Generated biographical information“ (long): With the BIOCOUPLY the SOEP provides consistent and continuous partnership histories for nearly all adult respondents. BIOCOUPLY is build on retrospective and prospective information at the time of each interview. The relationsship histories are provided on an annual basis.
biomarsm „Generated biographical information“ (long) : With BIOMARSM the SOEP provides consistent and continuous marital histories for nearly all adult respondents. BIOMARSM is build on the prospective information at the time of each interview. The martial histories are collected on a monthly basis from all adult SOEP-participants since their entry into the SOEP.
biomarsy „Generated biographical information“ (long) : With BIOMARSY the SOEP provides consistent and continuous marital histories for nearly all adult respondents. BIOMARSY is build on retrospective and prospective information at the time of each interview. The marital histories are provided on an annual basis.
einkalen „[deprecated] Spell data on income“ (long) : The income calendar is used to gain information about sources of income throughout the year. The respondent checks off for each month all appropriate sources of income.
lifespell „Spell Information on the Pre- and Post-Survey History of SOEP-Respondents" : The SOEP team regularly conducts drop-out studies to identify the whereabouts of attritors. These studies draw on official register data and allow us to determine whether a person is still living in Germany, is deceased, or has moved abroad since the last SOEP interview. The information is combined in a spell file LIFESPELL. This dataset reports all available information on the pre- and the post-survey history of all persons who have ever been a member of a SOEP household.
migspell „Migration history“(long) : MIGSPELL is derived from the migration biographies, which are collected from each new respondent of the IAB-SOEP migration samples M1 and M2. It contains data on the moves of foreign-born migrants as well as on the stays abroad of German-born respondents.
pbiospe „Generated biographical information“ (long) : The spell file PBIOSPE is based on the information on activity status over the life course, which is collected as a matrix from every respondent answering the Biography Questionnaire. The observations start at the age of 15 and end at the current age (up to age 65). To update the ongoing occupational career in PBIOSPE, information from the yearly Individual Questionnaire is also used.
refugspell „Migration history“ (long) : For migration biographies in the refugee samples, we created the spell data set REFUGSPELL. The variables in MIGSPELL and REFUGSPELL are derived from different instruments and only partially overlap. The data structure allows the data set to be linked with MIGSPELL if desired.
1992-2000
sozkalen „[deprecated] Spell data on social benefits“ : The file SOZKALEN provides spell data on receiving social assistance of households, defining begin, end, and censoring status of any period of receiving 3 different types of assistance. This file is set up, using information from the calendar, asked for the previous year (asked for the years 1992-2000). Thus, it contains information on a monthly basis.
Labeling SOEP-Core¶
The following explanations refer to the data sets of the subdirectory “raw” in your distribution file. There is no systematic variable naming for the long files above the subdirectory “raw”.
Labeling Scheme of Data Sets and Variables in SOEP-Core¶
To distinguish the multitude of data sets and variables, the SOEP uses systematic dataset and variable names for data in cross-sectional format. These names provide a lot of information for data users. Example of a data set name:
xp
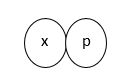
The first identifier of each data set name is the wave identifier (“x”). It can contain one or two letters. .
Each wave or survey year can be assigned using a letter in the alphabet:
| 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 |
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q |
| 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 |
| r | s | t | u | v | w | x | y | z | ba | bb | bc | bd | be | bf | bg | bh |
As can be seen from the table, the sample data set “xp” contains survey information from the survey year 2007.
The second identifier of each data set name is the abbreviation for the respective survey instrument or, for generated data sets, the name of the content (“p”).
- h= Household
- hbrutto= Household Gross
- hgen= Generated Household Data
- p= Individuals
- pbrutto= Person Gross
- p_mig= Migrants
- pgen= Generated individual data
- jugend = Youth (Ages 16-17)
- school= Pupils (Ages 11-12)
- vp= Deceased persons
- luecke= Gap Questionnaire
- hkind= Information for children from household questionnaire
- pequiv= Cross National Equivalent File
- pkal= Calendar
Further examples:
- bah = Wave „ba“ (Survey year 2010), Household data sets
- bfschool= Wave „bf“ (Survey year 2015), Pupils data sets
- zhgen = Wave „z“(Survey year 2009), Generated Household data sets
Variable names in the SOEPcore data files follow basic conventions: First, there are datasets with “speaking” variable names, where the variable name itself conveys something about the information stored in this variable. This is usally the case when the dataset is generated.
For the original datasets such as $H, $P and $KIND, the variable names are set up “around” the unit of analysis (individual - “p”, household - “h”, and child - “k”) and show before this indicator the wave in which the data was collected and after it the reference where the question can be found in the original survey instrument (see Figure 9 for an overview).
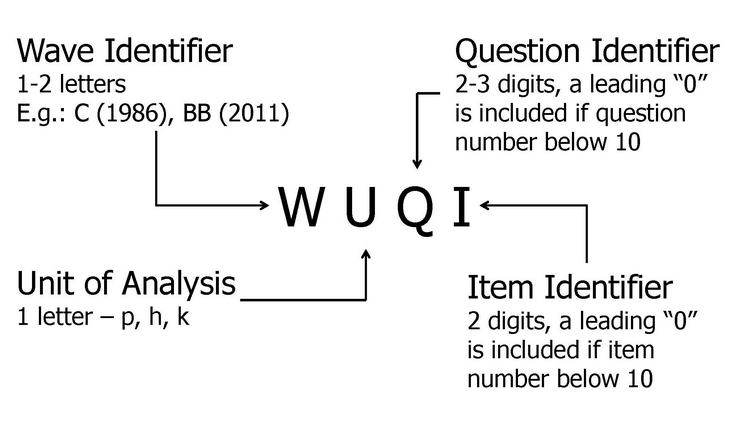
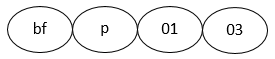
Example for a variable name: bfp0103
The first identifier of a variable name is the wave (i.e. „bf“) Every wave or rather every year can be assigned to a specific letter in the alphabet:
| 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 |
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q |
| 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 |
| r | s | t | u | v | w | x | y | z | ba | bb | bc | bd | be | bf | bg | bh |
As can be seen from the table, the variable „bfp0103” contains information from the survey year 2015.
The second identifier of a variable is the abbreviation for the respective survey instrument or the type of information („p“)
- h= Household
- hbrutto= Household gross
- hgen= Generated household data
- p=Individual data
- pbrutto= Person gross
- p_mig= Person migrants (M1 und M2)
- pgen= Generated individual data
- jugend = Youth (Ages 16-17)
- school= Pupils (Ages 11-12)
- vp= Deceased people
- luecke= Gap Questionnaire
- hkind= Children information from the household questionnaire
- pequiv= Cross National Equivalent File
- pkal= Calender
The third identifier of a variable name describes the question number („01“) and a possible fourth identifier describes the position of the answer category („03“).
The example variable „bfp0103“ describes the „satisfaction of work“. The variable was raised in 2015 („bf“) and it can be found in the individual questionnaire („p“). In the associated individual questionnaire, the variable can be found in the first question („01“) under the third position of all answers categories („03“).
More examples: - ap06 = Wave „a“ (survey year 1984), Individual Dataset, Question 6 - th1603 = Wave „t“ (survey year 2003), Household Dataset, Question 16, Item 3 - lp10312= Wave „l“ (survey year 1995), Individual Dataset, Question 3, Item 12 - bap15604 = Wave „ba“ (survey year 2010), Individual Dataset, Question 156, Item 4
Since the data structure is getting richer every year, we extended the common variable naming convention WUQI, starting with the wave „bh“(2017). Additionally, we provide our users with an „instrument“ variable that contains all our survey instruments for each analyzing unit.
Extended Variable Naming Conventions¶
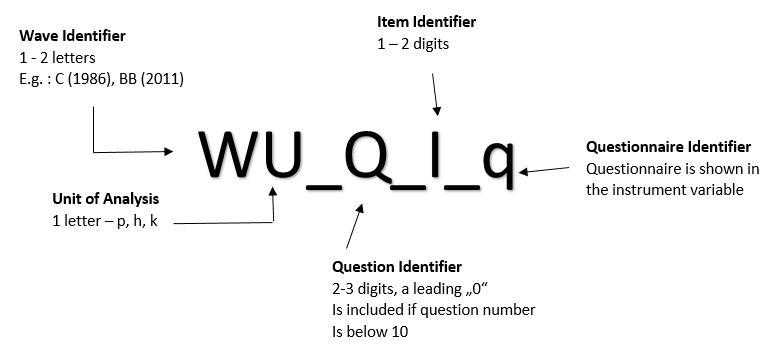
We added an underscore between question identifier and item identifier to separate question and item visually. In addition, a questionnaire identifier was introduced, which is also separated by an underscore from the item. This new version of naming variables only comes to use, if the survey instrument differs from the „original“ instrument.
Due to our different samples in the SOEP, there are some samples groups that are getting sample specific questions, like the migrant sample that started in 2013. For that specific group, we created an extended individual questionnaire, with migrant specific question and standard SOEP questions that are asked every year. For the specific questions, you can use the instrument variable to see the variables` source.
Let`s take a look at the variable bhp109_01_q57
- bh= Year 2017
- P= Person questionnaire
- 109= Question 109
- _01= First Item
- _q57= ?
To know which questionnaire is the right one, you have to take a look at the instrument variable.
| Value | Questionnaire |
|---|---|
| 50 | 2017 Individual Questionnaire (A-L1 ; PAPI) [soep-core-2017-pe] |
| 51 | 2017 Individual Questionnaire (A-L3 ; CAPI) [soep-core-2017-pe2] |
| 52 | 2017 Individual Questionnaire (L2-L3 ; CAWI) [soep-core-2017-pe3] |
| 53 | 2017 Individual Questionnaire (N; CAPI) [soep-core-2017-pe4] |
| 54 | 2017 Individual Questionnaire (M1-M2 Re-Surveyed; CAPI) [soep-core-2017-p-m12] |
| 55 | 2017 Questionnaire Individual-Biography (M1-M2 First-Surveyed; CAPI) [soep-core-2017-pb-m12-erst] |
| 56 | 2017 Questionnaire Individual-Biography (M3-M5 First-Surveyed; CAPI) [soep-core-2017-pb-m345-erst] |
| 57 | 2017 Questionnaire Individual-Biography (M3-M4 Re-Surveyed; CAPI) [soep-core-2017-pb-m34-wieder] |
| 58 | 2017 Biography Questionnaire (A-L1 First-Surveyed; PAPI) [soep-core-2017-ll] |
| 59 | 2017 Biography Questionnaire (A-L3; N First-Surveyed; CAPI) [soep-core-2017-ll2] |
The instrument variable for identifying the exact questionnaire can be found in the respective data set. The value Q57 of the example identifies the individual biography questionnaire for re-surveyed respondents of the samples M3/M4 as the variable source. If you are now interested in the direct question in the questionnaire, open the individual biography questionnaire for refugees (Re-Surveyed), look for question number 109 and look at the first item. The variable bhp109_01_q57 was raised with the following question:
Q109: When was the beginning of the integration course?
|
Using the variable name and the instrument variable, you can easily identify the corresponding question in the corresponding questionnaire:
- bhp109_01_q57
- bh= Year 2017
- P= Individual questionnaire
- 109= Question 109
- _01= First Item
- _q57= 2017 Questionnaire Individual-Biography (M3-M4 Re-Surveyed; CAPI) [soep-core-2017-pb-m34-wieder]
Missing Conventions¶
Survey variables might be missing, i.e. without a valid code or value for different reasons. In the SOEP, negative values are not valid for any variable, but are used instead to code different reasons for missing information. There are two distinctions for missing values: they may originate in the respondent’s answer or in the survey design. The respondent may refuse or not know an answer or she may report invalid values on the one hand, and the interview design may exclude respondents with certain characteristics from some questions on the other (e.g. men will never be asked if they are pregnant). The following codes apply both for SOEPCore and SOEPlong, also shown here:
| Code | Label |
|---|---|
| -1 | no answer / don’t know |
| -2 | does not apply |
| -3 | implausible value |
| -4 | Inadmissable multiple response |
| -5 | Not included in this version of the questionnaire |
| -6 | Version of questionnaire with modified filtering |
| -8 | Question not part of the survey program this year¹ |
¹Only applicable for datasets in long format.
A person might refuse to answer a question, which happens more often in sensitive questions (e.g. income related questions), or may just not know the answer to a question. In such a case, the missing code is “-1” for “no answer / don’t know”. Note that the SOEP does not distinguish between the refusal to answer and a true “don’t know”. Information may be missing when a question is not asked because it is not relevant for a specific person, e.g. owner-occupiers will not be asked about the amount of rent they pay. In such cases, the question “Does not apply” to this person, and the variable receives a code of “-2”. Sometimes invalid answers are encountered, when respondents fill out a PAPI interview themselves or the interviewer mistypes an answer, e.g. persons cannot work more than 168 hours a week. In such a case, multiple checks are carried out, and if the inconsistency remains, the variable is recoded “-3 Implausible value”. Some questions contain multiple answer possibilities, where the respondents are asked to pick one and only one answer. In the SOEP PAPI instruments, sometimes respondents ignore this request and provide more than one answer, e.g. they mark “very good” and “good” when asked about their current health status. In such cases, if the correct answer cannot be determined from the questionnaire itself, the code “-4 Invalid Multiple Answers” is given to this variable. With the extension of the SOEP in recent years, entirely new samples have been added to the core. In these samples, sometimes questions are left out completely, e.g. to shorten the questionnaire or because the focus of the sample is different as in some of the related studies. In such a case, the variable will be set to “-5 Not included in this version of the questionnaire” for an entire subsample. With the use of CAPI, recent developments include an “integrated” person questionnaire, i.e. the biography part and the “regular” part of the questionnaire are asked as one. Some of the questions in the biography part are repeated in the regular part. While in the PAPI mode, the respondent will answer the same question twice, the CAPI allows to filter the respondent around the question if it has already been asked. These cases are very rare - if they occur, they receive a code “-6 Version of questionnaire with modified filtering”.